
Running your own embedding model api server - Part1
Developers often rely on the OpenAI embedding API to generate embeddings from data, enabling the construction of LLM apps or the implementation of semantic search. The following code snippet demonstrates how text can be converted into vectors using the OpenAI embedding API, returning the processed token length:
import openai
openai.api_key = "YOUR_API_KEY"
text = "This is the text for which you want to create an embedding."
response = openai.Embed.create(engine="text-davinci-002", text=text)
embedding = response["embedding"]
However, if you are concerned about API pricing or data privacy, the OpenAI embedding API is not your only option. There are several open-source models available that you can leverage to build your own embedding API server. In this article, we will guide you through the process of building your own embedding API, similar to OpenAI’s embedding API.
Selecting the Model
Before building your embedding API, it’s important to choose a suitable model for your needs. MTEB is a good benchmark for evaluating the performance of text embedding models across diverse tasks. The benchmark provides rankings for various text embedding models based on their performance.
When selecting a model, consider the specific task you want to accomplish. For example, if you are focusing on a retrieval task to provide context for LLM, the retrieval task score is crucial. The multilingual-e5-large model achieves the highest score for retrieval tasks, followed by e5-large-v2 and e5-base-v2. Since this article only focuses on English language support, e5-large-v2 or e5-base-v2 are recommended choices. The former has 330M parameters, while the latter has 110M parameters. If you have limited RAM, it is advisable to choose e5-base-v2. However, if you have sufficient RAM, e5-large-v2 can be a suitable option.
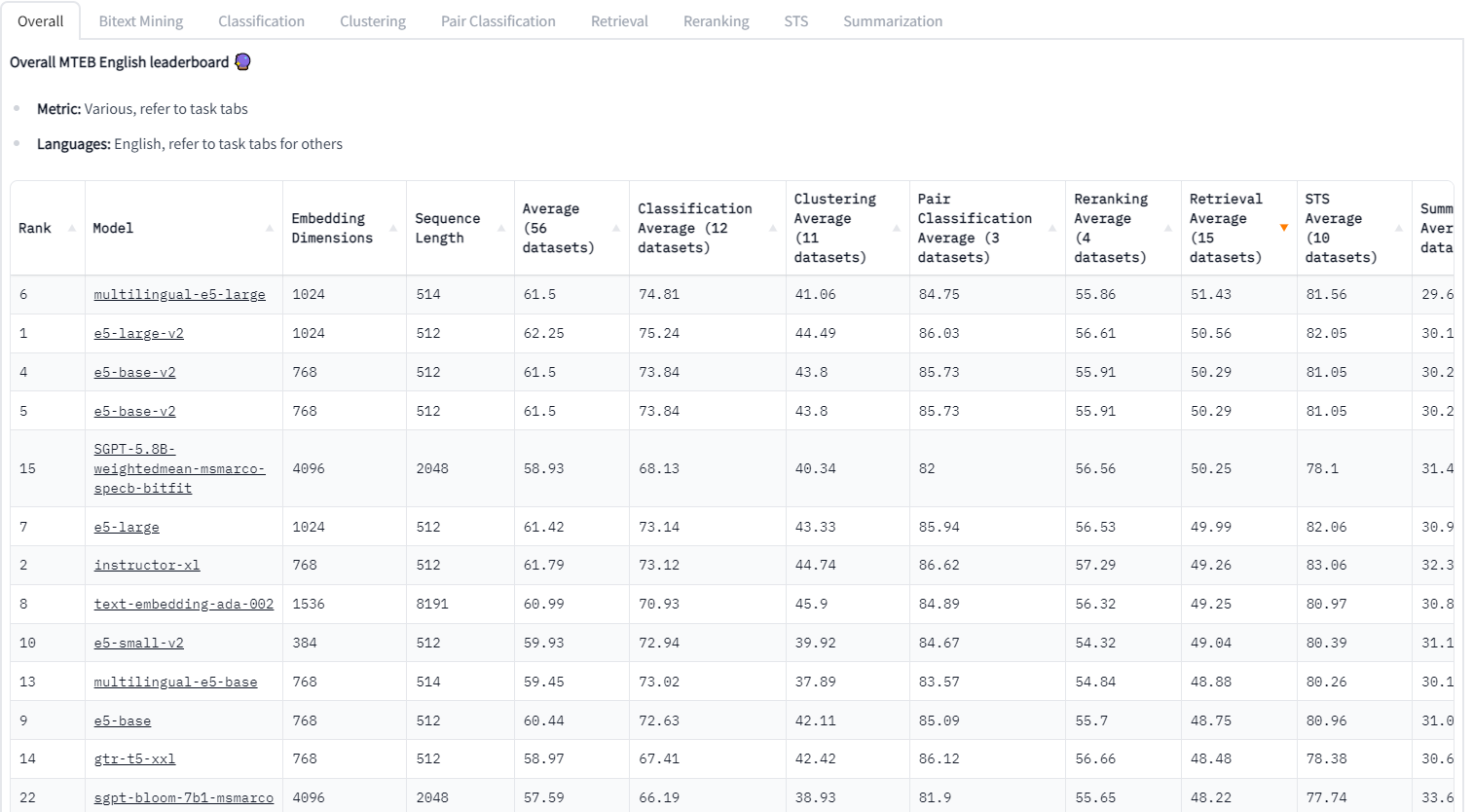
It’s worth noting that OpenAI’s text-embedding-ada-002 model is ranked 7th in the benchmark. Although multilingual-e5-large performs better according to the benchmark, there is a significant difference in sequence lengths. While multilingual-e5-large has a sequence length of 512, text-embedding-ada-002 has a sequence length of 8191. This means that text-embedding-ada-002 can handle more data per embedding, potentially leading to better performance when building LLM apps. Therefore, this difference should be considered when utilizing the model.
Running e5-base model on Your Machine
You can find example code for running the e5-base model on the Hugging Face repository:
https://huggingface.co/intfloat/e5-base
To execute the code, you need to install PyTorch and the Transformers library, which can be easily done using pip.
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ".
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-base')
model = AutoModel.from_pretrained('intfloat/e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
After installing the necessary dependencies, you can run the above code to obtain the embeddings. It’s important to note that there are two steps involved in processing the input_texts array to generate the embeddings. First, the tokenizer tokenizes the input texts. You can inspect the tokenized result and determine the length of tokens from the tokenizer’s response.
The code snippet below allows you to calculate the token length of inputs and the tokenized result. Being aware of this information is helpful when checking if the sequence length is within the model’s limit while building the API. Additionally, returning the processed token length in the API response can be useful for consumption.
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
print(len(torch.flatten(encoded_input.data['input_ids'], 0)))
for ids in encoded_input.data['input_ids']:
print(tokenizer.convert_ids_to_tokens(ids))
Introduction to BentoML
Now, let’s explore how to create an API server. While you may consider using FastAPI or Flask to build a simple HTTP endpoint and insert a sample model code into an API handler, there are several considerations when creating a robust API server. What if you want to process multiple requests as batches or measure the model’s running time? What if you want to add more models to the API server? This is where BentoML comes in handy. BentoML is an end-to-end solution for model serving, simplifying the process of serving and deploying models.
To install BentoML, run the following command:
pip install bentoml
Saving Models with BentoML
Let’s now explore how to save models using BentoML. BentoML provides native support for various frameworks such as PyTorch and Transformers, making it easy to serve and deploy models. In our case, since we used a pre-trained tokenizer and model, we will save two separate models: one for the tokenizer and the other for the actual text embedding model.
import bentoml
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
bentoml.transformers.save_model("e5_base_tokenizer", tokenizer)
bentoml.transformers.save_model(
"e5_base_model",
model,
labels={ # user-defined labels for managing models in Yatai
"owner": "nlp_team",
"stage": "dev",
},
signatures={
"__call__": {
"batchable": True,
"batch_dim": 0,
},
}
To save the models, execute the above code using python model.py. After running the code, you can obtain a list of the saved models. That’s it! Now your models are saved and ready for serving.
$ bentoml models list
Tag Module Size Creation Time
e5_base_model:hiitriq7uscd7w34 bentoml.transformers 1.04 GiB 2023-07-11 04:34:31
e5_base_tokenizer:hiitria7uscd7w34 bentoml.transformers 21.13 MiB 2023-07-11 04:34:30
Conclusion
In this article, we explored the process of saving models using BentoML. We focused on BentoML’s support for multiple frameworks, particularly PyTorch and Transformers, which are commonly used for serving and deploying models. By utilizing BentoML, we were able to save both the tokenizer and text embedding model separately.
In the next part of this series, we will take a step further and build an actual API server using BentoML. We’ll also explore advanced features such as adaptive batching and creating a Docker image. Stay tuned for part 2, where we’ll demonstrate how to deploy your saved models and leverage advanced functionalities to enhance your API server.